大数据测试,工作内容主要有:数据测试、模型测试;同时在不同的业务阶段,工作的重心不同,数据质量体系也会有不同的倾向,要全局的了解大数据测试,必须先明白大数据的架构,工作过程
大纲
1 | 大数据架构 |
大数据架构
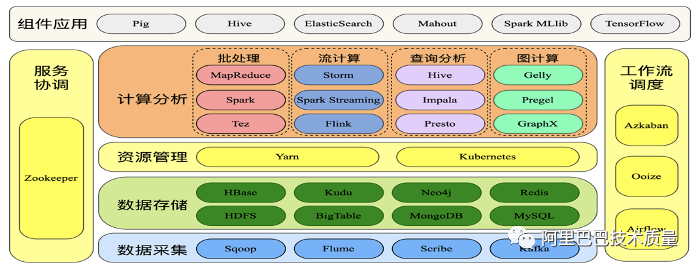
常见的大数据架构主要有Hadoop(分布式文件存储、计算系统);由分布式文件系统(HDFS)/集群资源管理器(YARN)分布式计算框架(MR/mapreduce)构成;其中HDFS负责管理存储数据,YARN负责管理集群中的计算资源,调度和执行工作任务;
组件:核心组件如下
1 | HDFS:分布式文件存储系统;实际存储的是文件,有备份机制,支持数据一次性写入(每次写入生成一个独立文件),不支持数据修改,支持大规模的数据查询,特点是容错,高吞吐量,易弹性扩容; |
组件特性: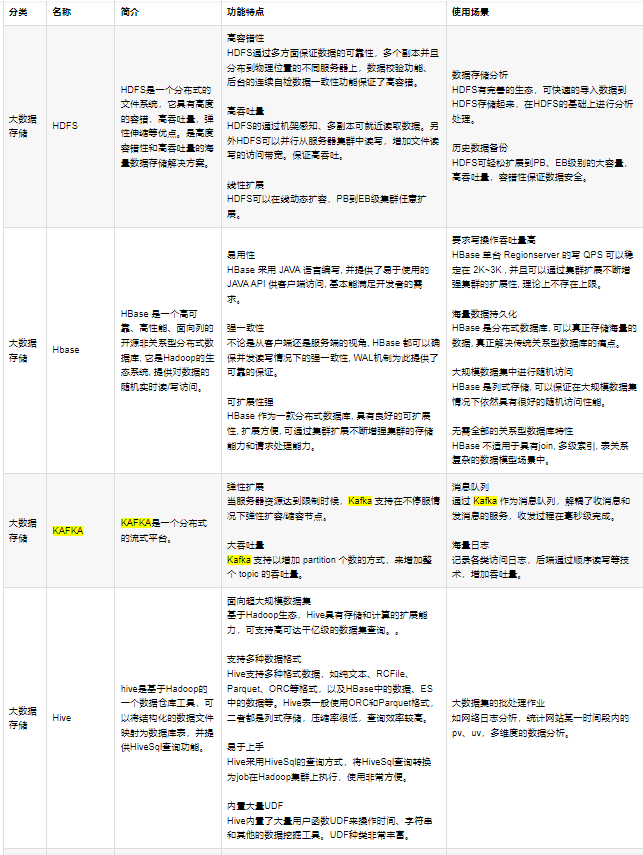
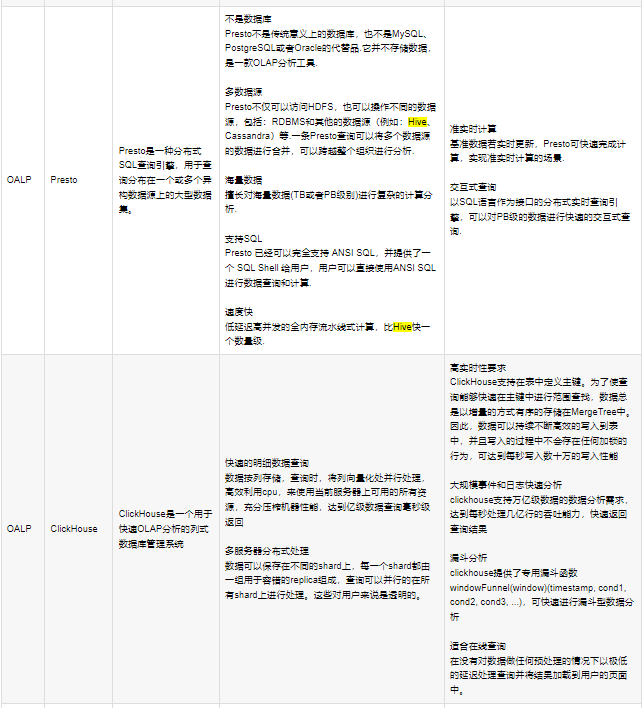
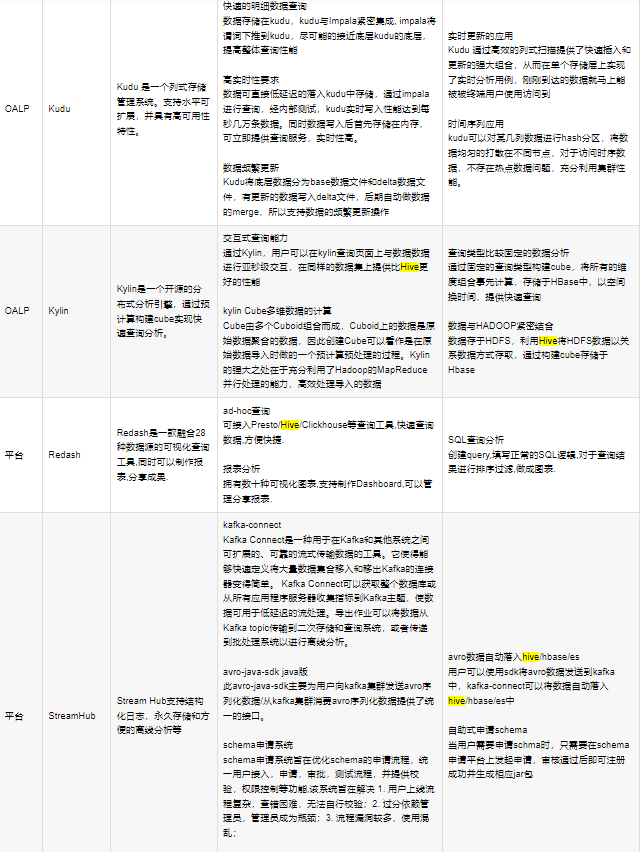

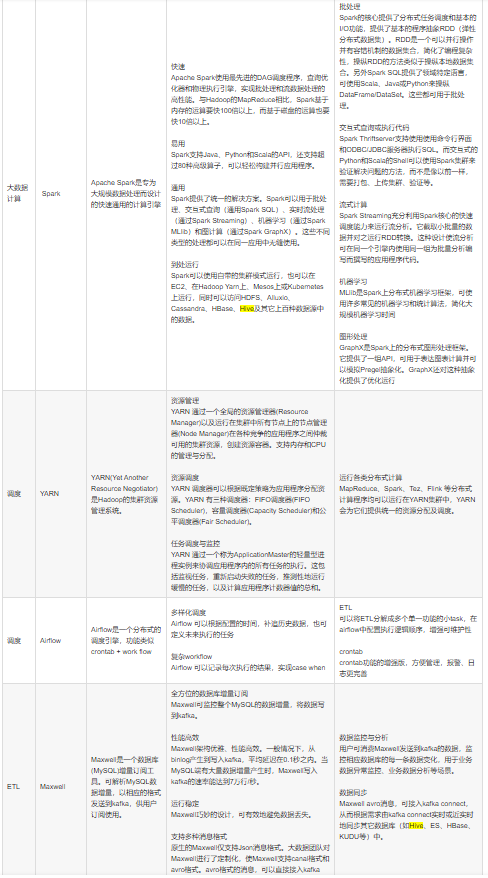
参考架构:
传易音乐大数据架构
传易hadoop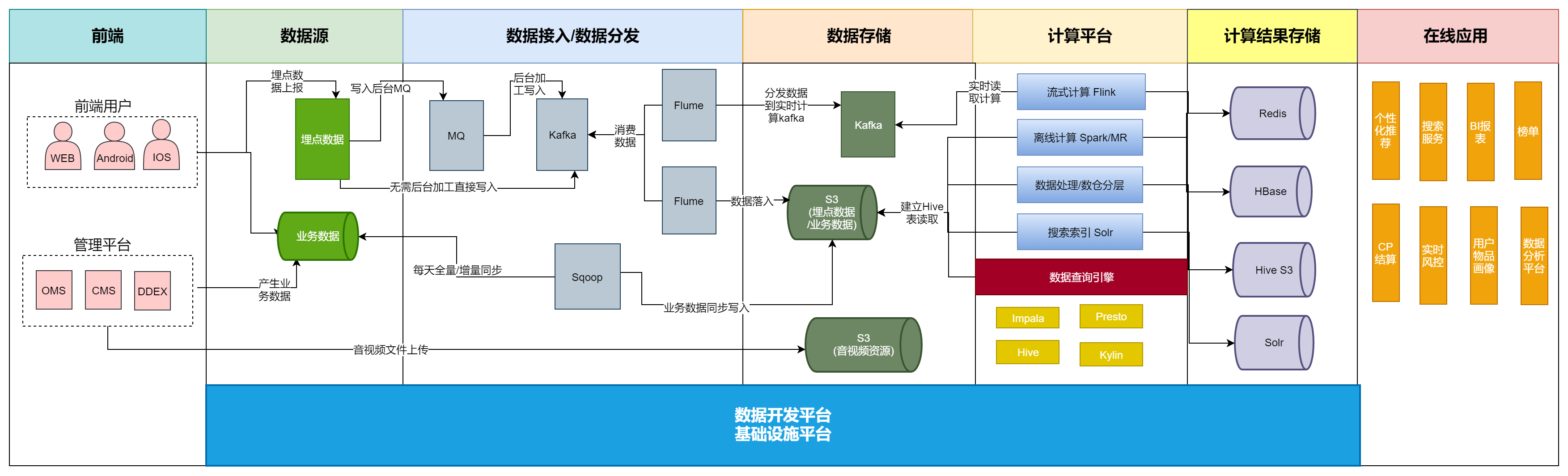
传易数仓架构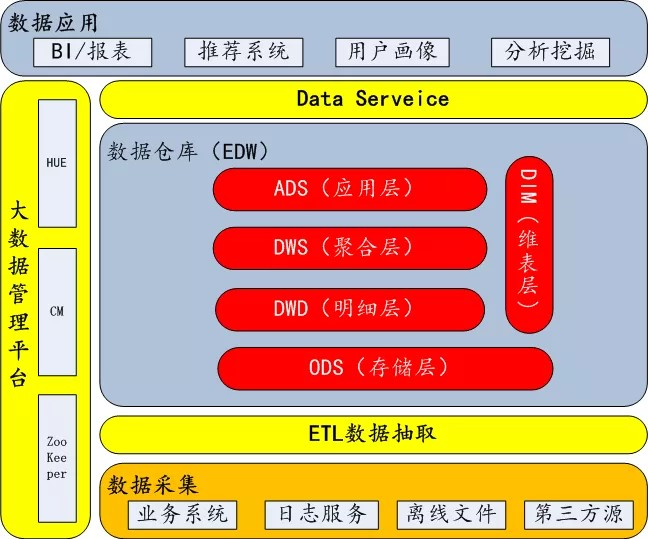
数据架构(数仓)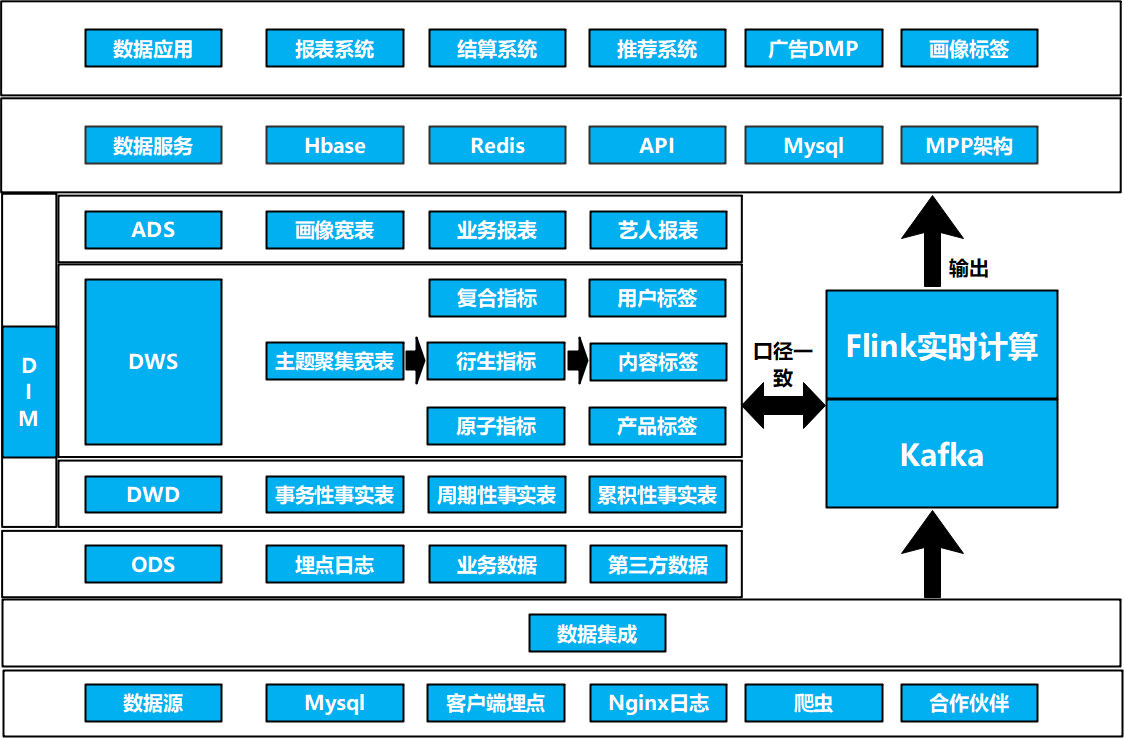
数据架构–横向数据分层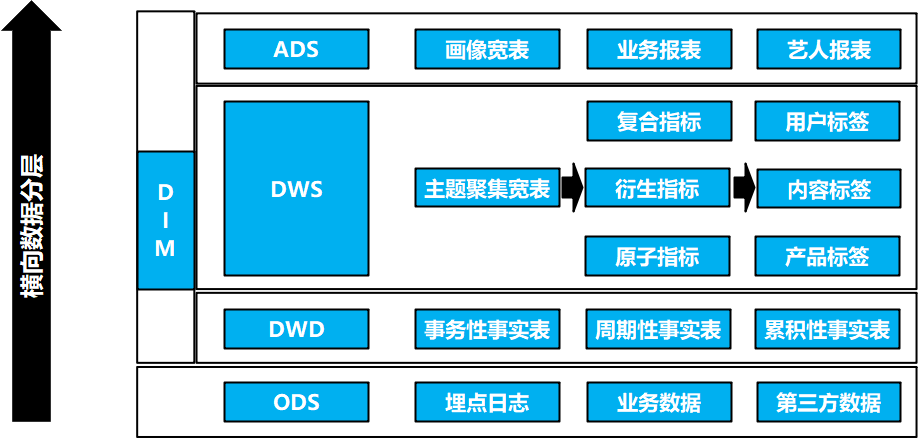
数据架构–纵向数据分层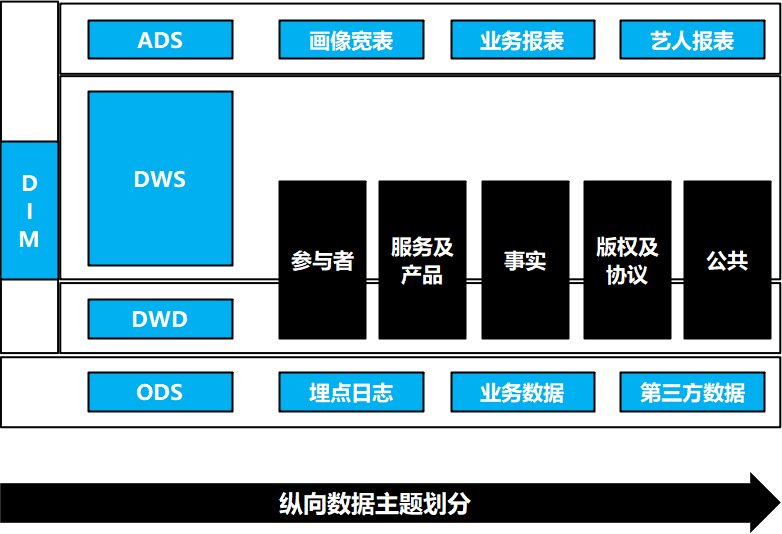
传易大数据架构总述:
传易架构的特点是处理的数据量大,数据来源复杂,人员多,业务应用广;存在无文档资料维护;测试介入低,质量不可度量;无测试环境,依赖线上数据开发测试,流程不规范,安全性差;缺乏标准和度量体系,投入产出比无法度量等问题;
数据测试
数据测试前,需要对数据质量形成共识;数据的价值是由需求方决定的,能满足需求方/使用方需求的数据才能称得上好数据
标准
数据质量评测方向
数据质量我们一般从以下六个维度评判,同时我们往往还需求考虑数据的(+安全性),评价这些维度往往需要用到监控数据和历史数据:
1 | 完整性:数据不多不少。数据条数完整,类型完整,参数完整;不重复,看是否有异常类型或者异常值(枚举外); |
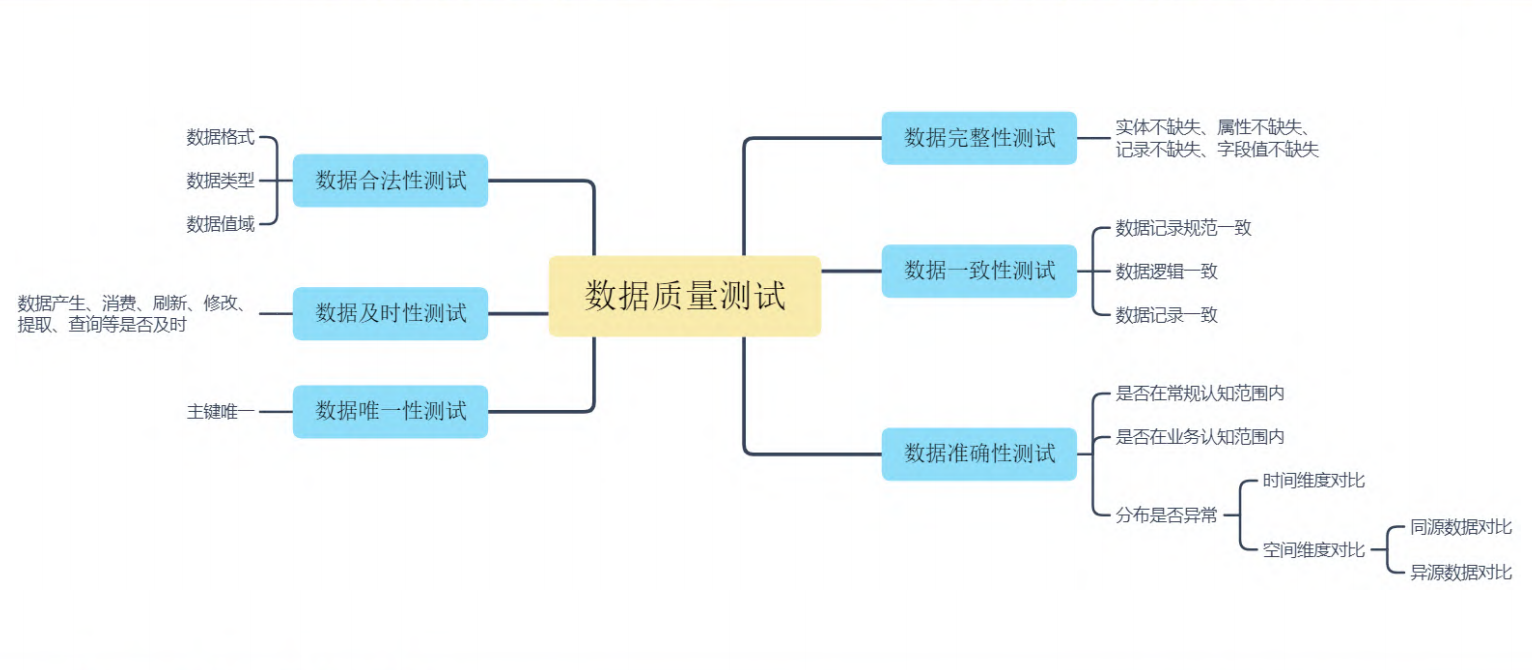
以上是测试时评判的方向,测试过程也需要有标准来评判有效性,如下:(理论不同对象/不同阶段都应该有标准)
测试活动度量标准
1 | 覆盖率 |
数据质量度量标准
除了测试时,需要考虑的场景外,还需要对整体的数据质量好坏进行评判,以下为数据质量的优劣评判标准
1 | 98%:全年可用天数达到98%以上,即服务不达标天数全年不超过7天。 |
以上指标为传易的定量的标准,以下为美团的定量的标准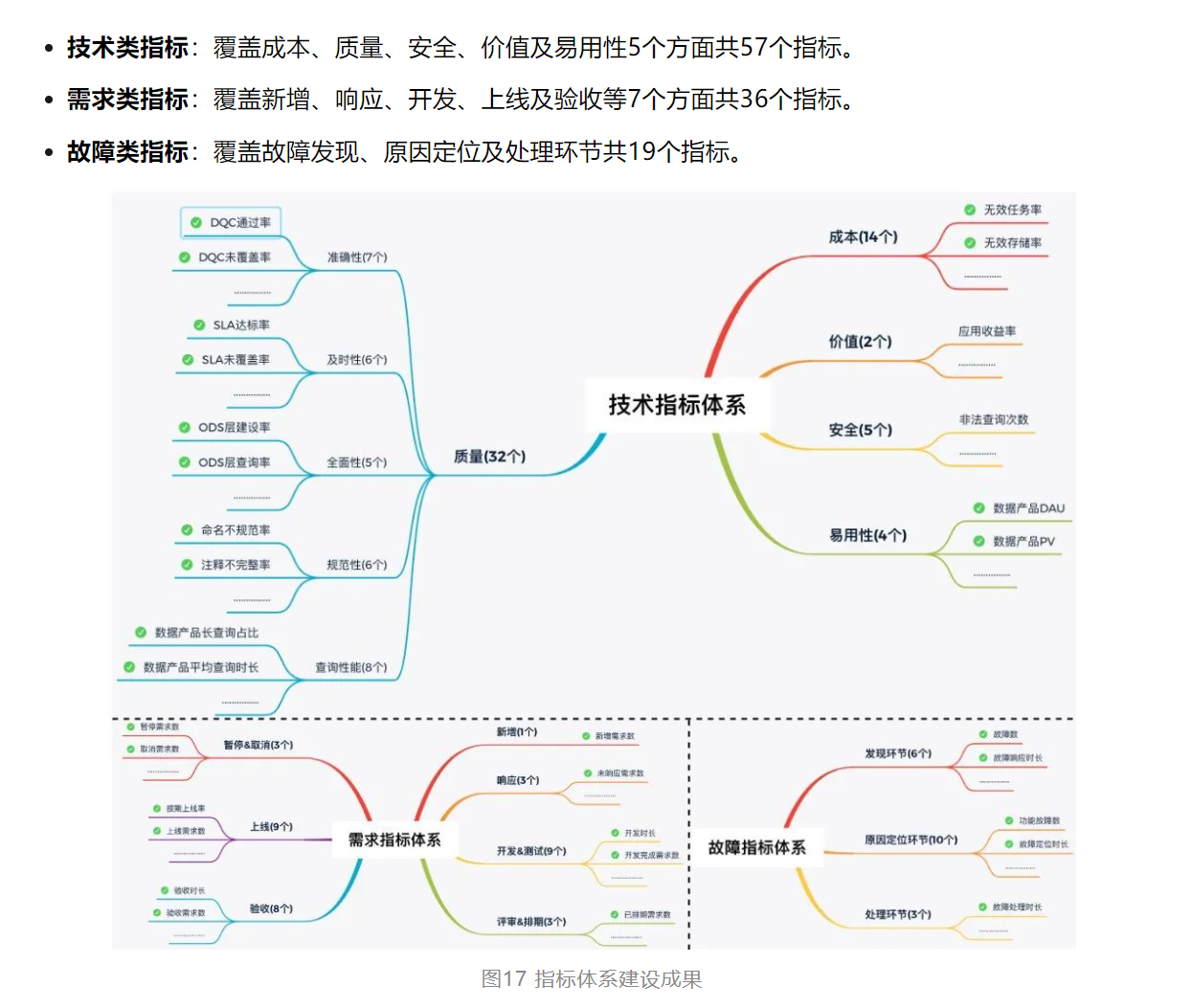
数据质量评测流程
要想把控数据质量,往往需要介入数据的全生命周期;需要有标准可依,有规范进行约束,有监控数据可查,有工具可用来进行评测,流程结果可量化,并且可以持续运营迭代体系:
1 | 业务分析--分析数据流(流程图)、数据特性(计算型/时效型) |
测试执行
数据治理可参考的切入阶段
数据质量三板斧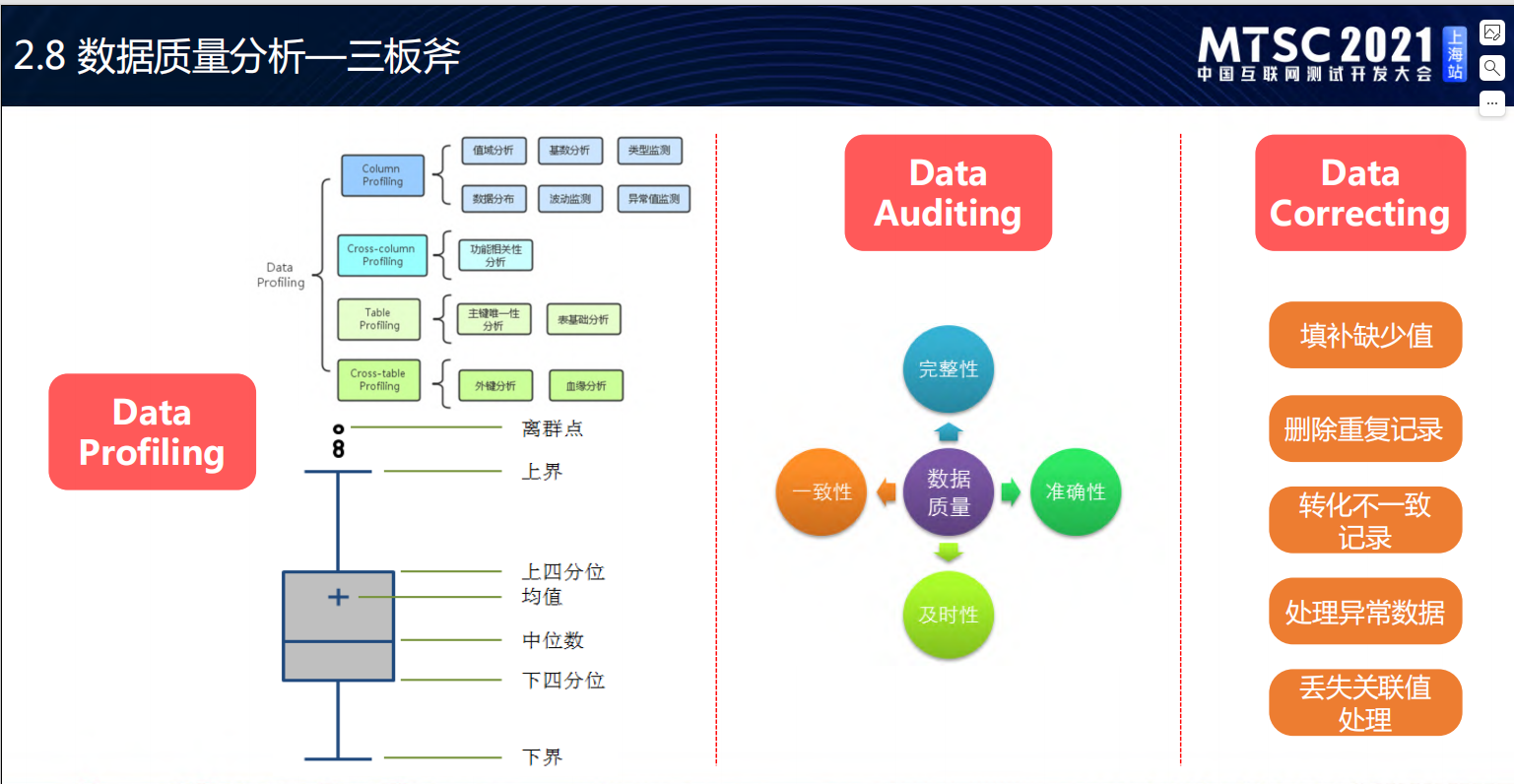
数据功能测试
三板斧:数据分析技巧
测试范围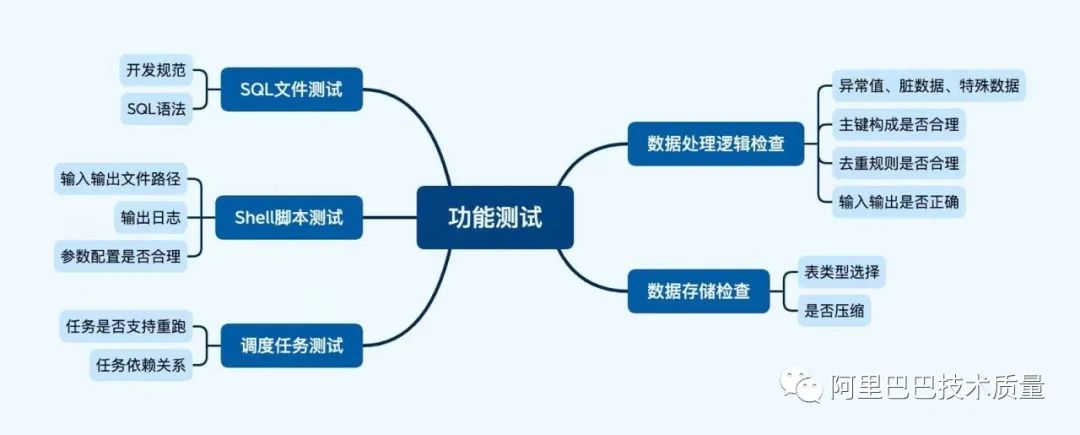
功能测试,很重要的一环是ETL:ETL测试维度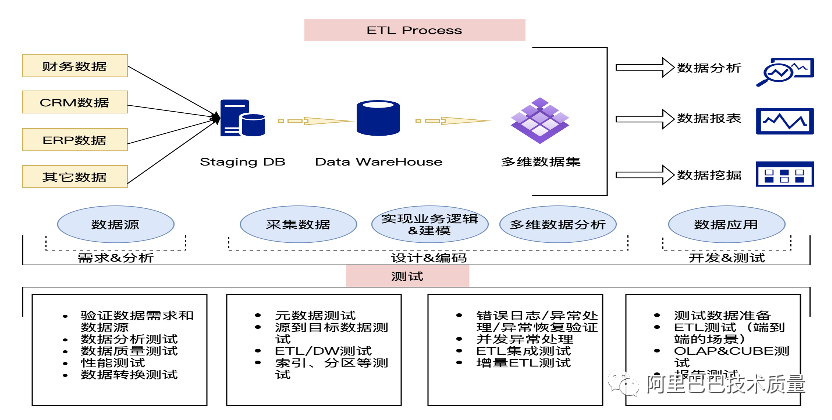
离线ETL测试步骤:核心在数据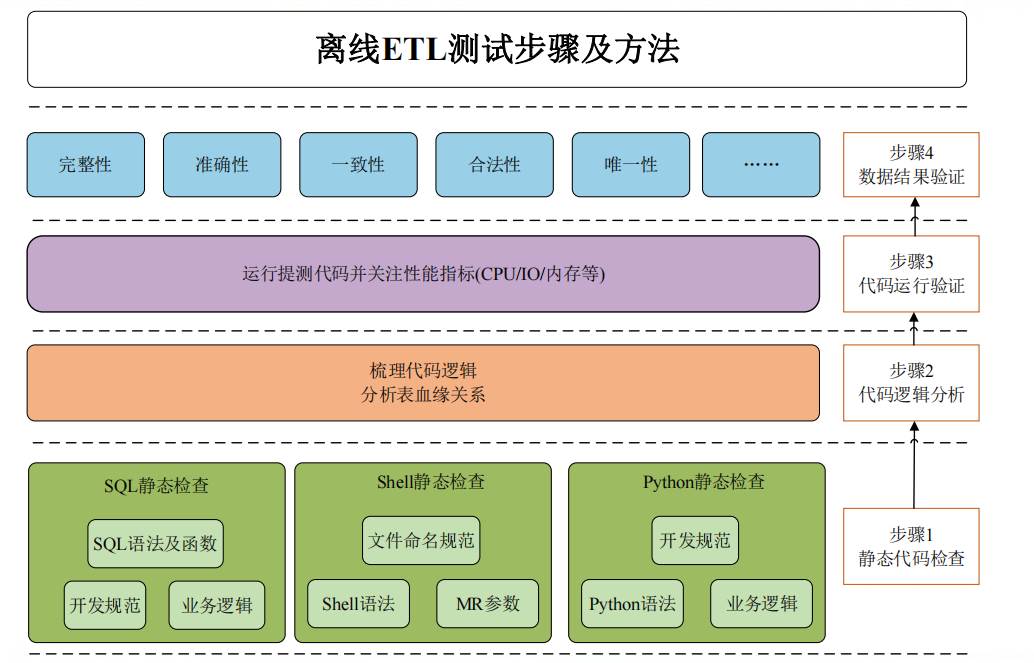
实时数据ETL:核心除了数据、还有性能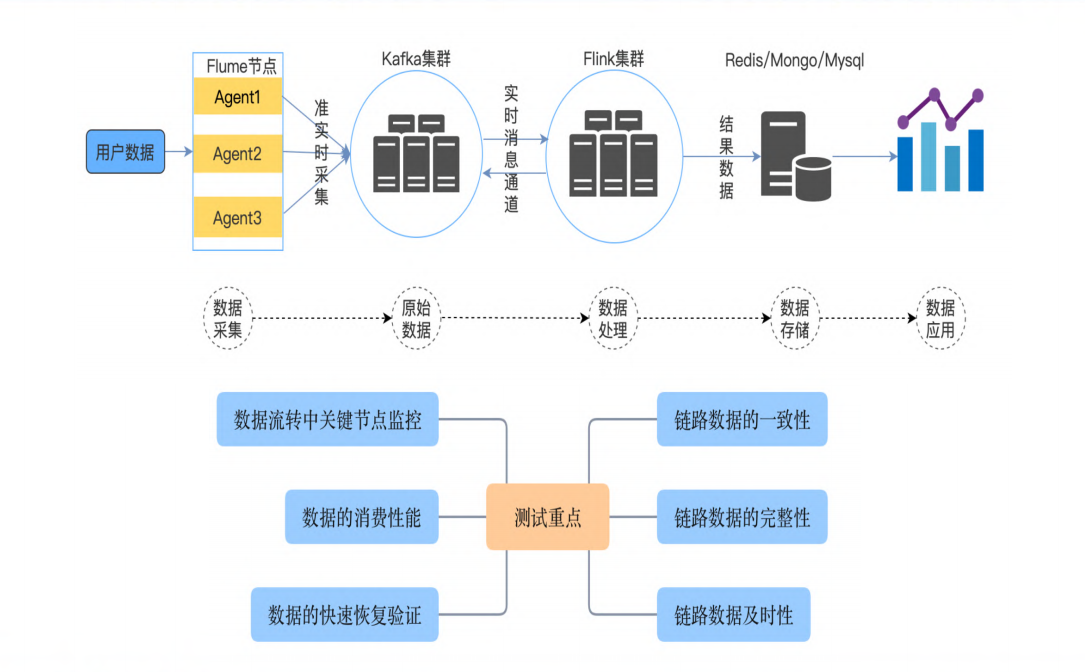
数据仓库分层测试
项目测试经验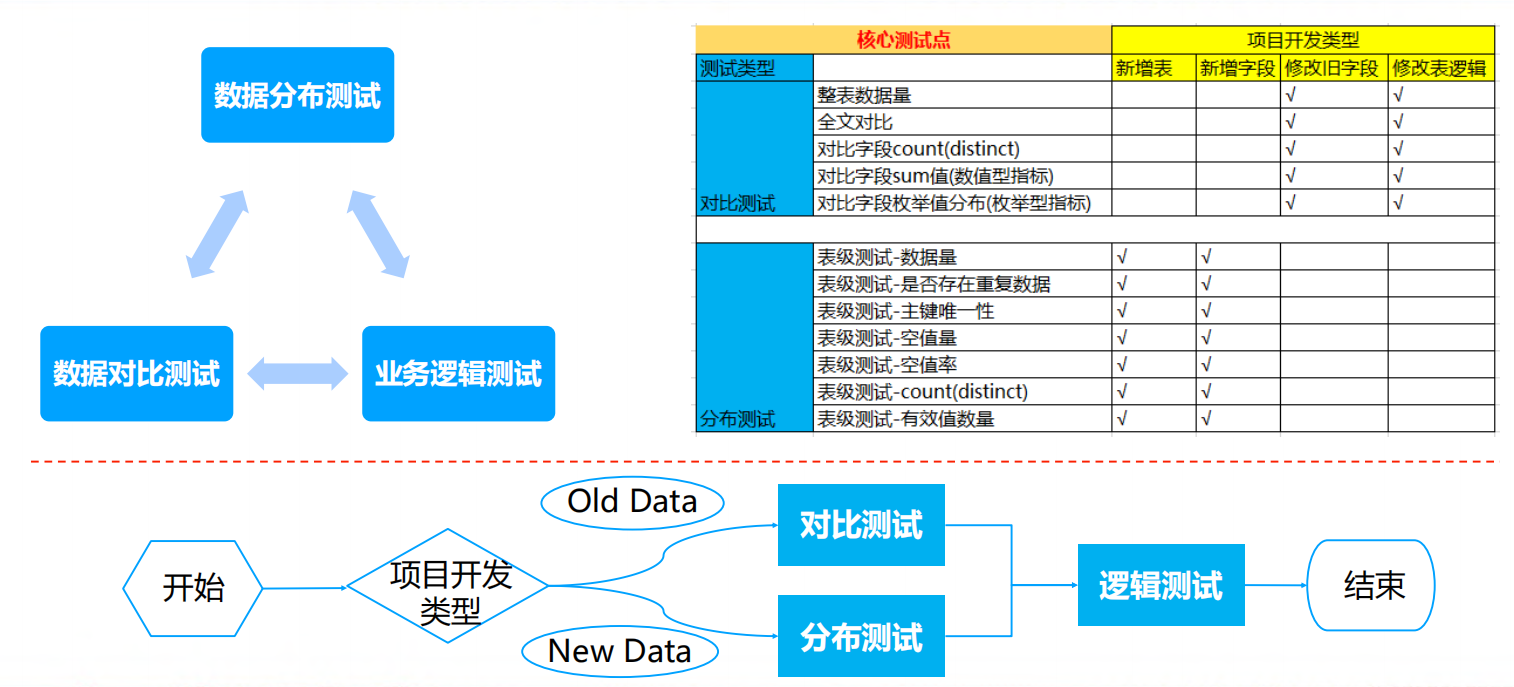
数据性能测试
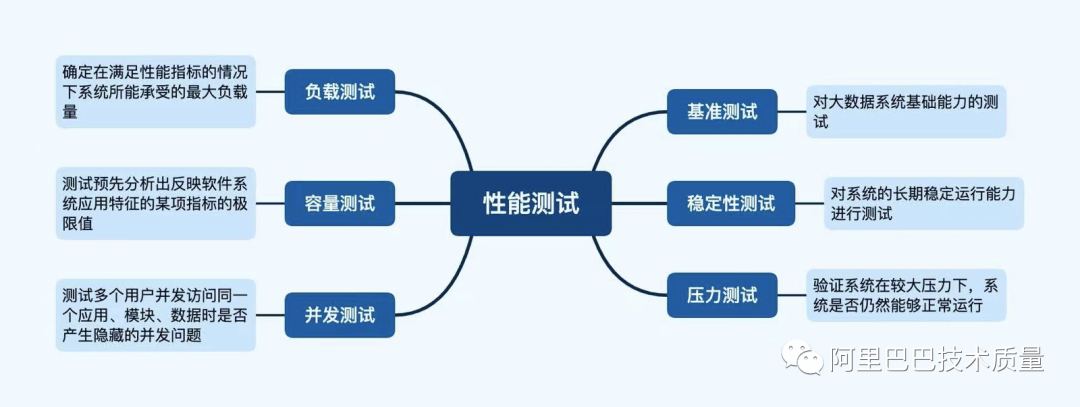
大数据性能工具: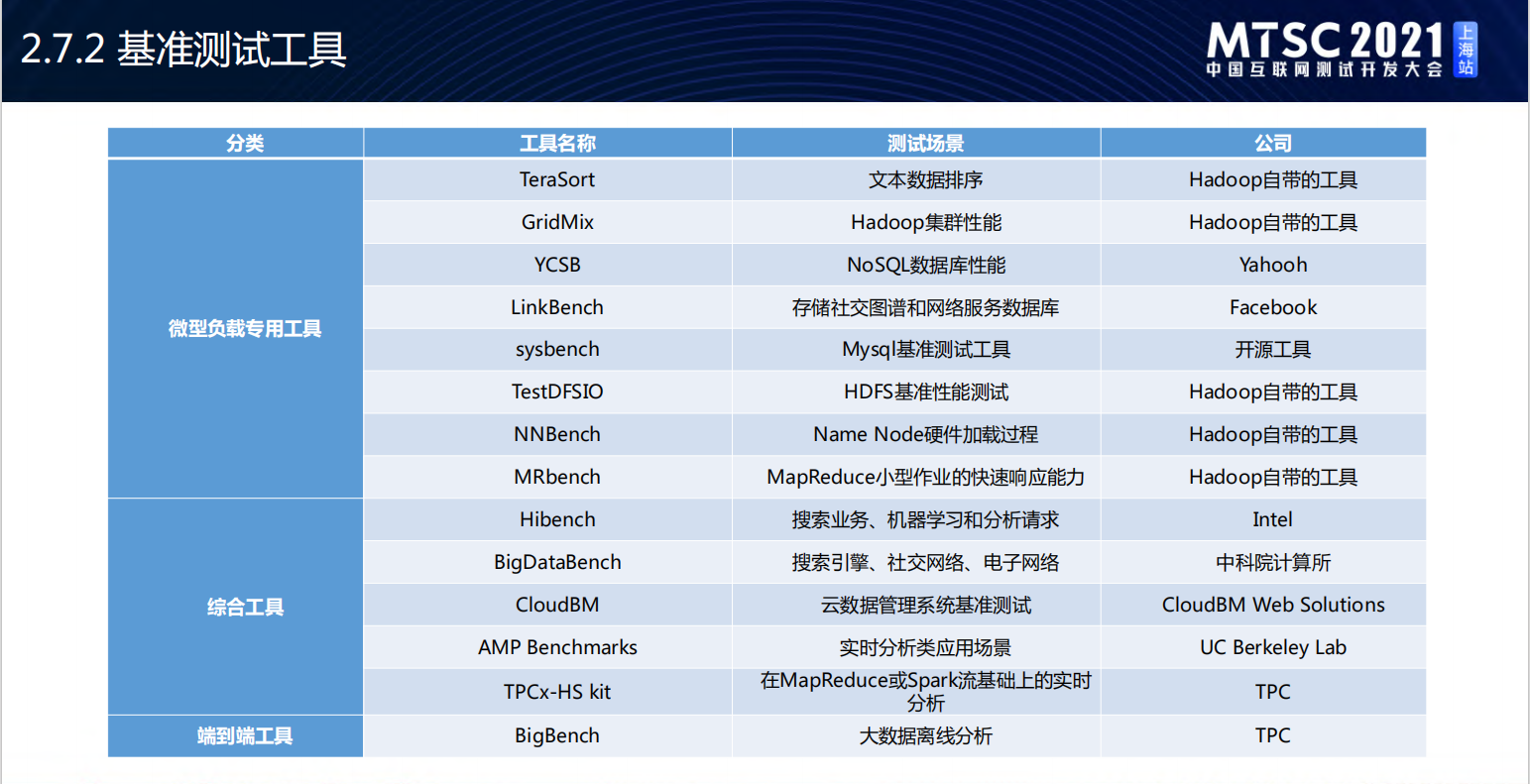
数据安全测试
以上的数据质量评测标准未说明安全情况,数据安全需要考虑数据本身的安全(隐私脱敏),流程安全,权限管控、安全监控,故在此处说明,安全需要覆盖的场景如下: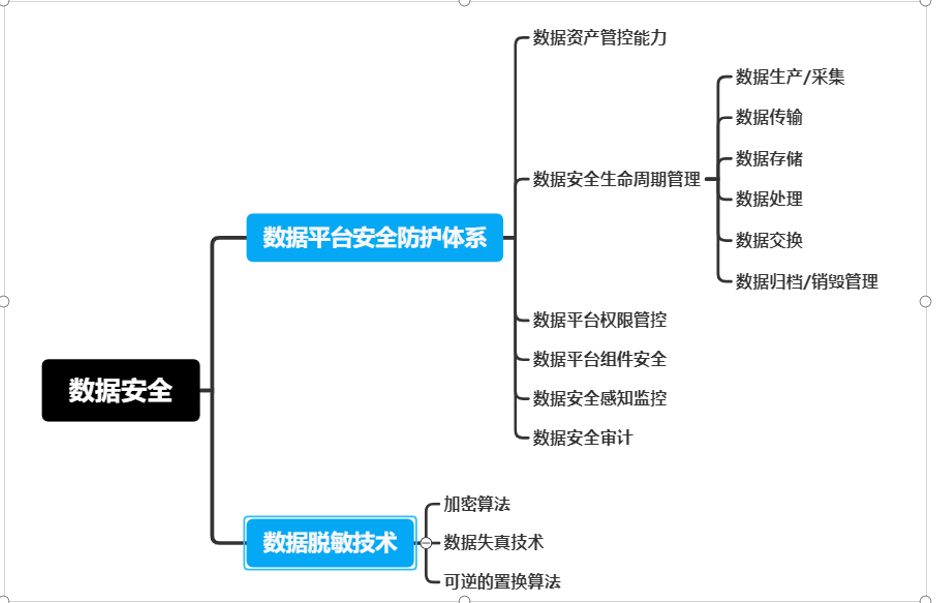
数据安全实施策略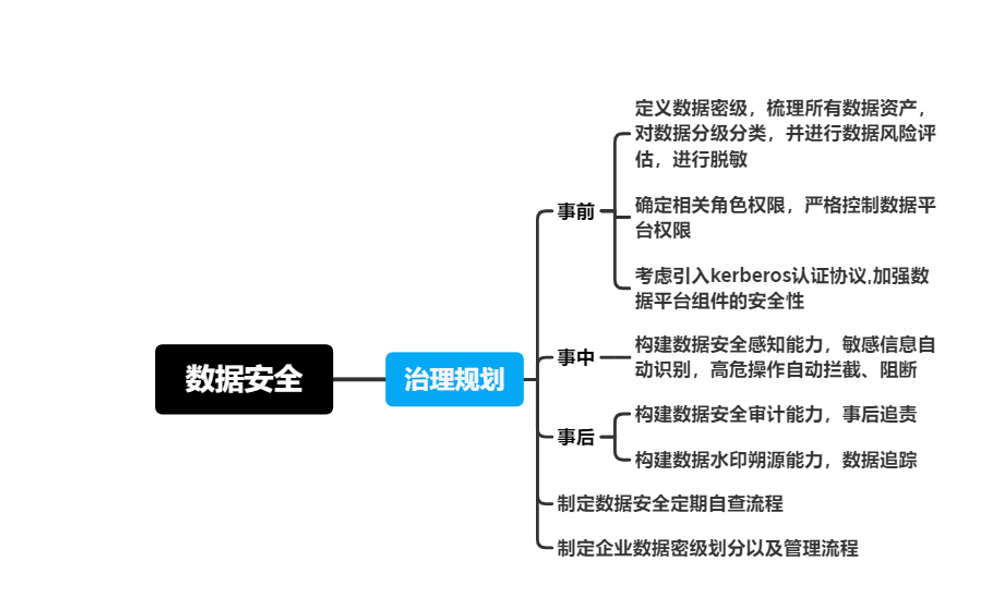
数据质量问题处理链路
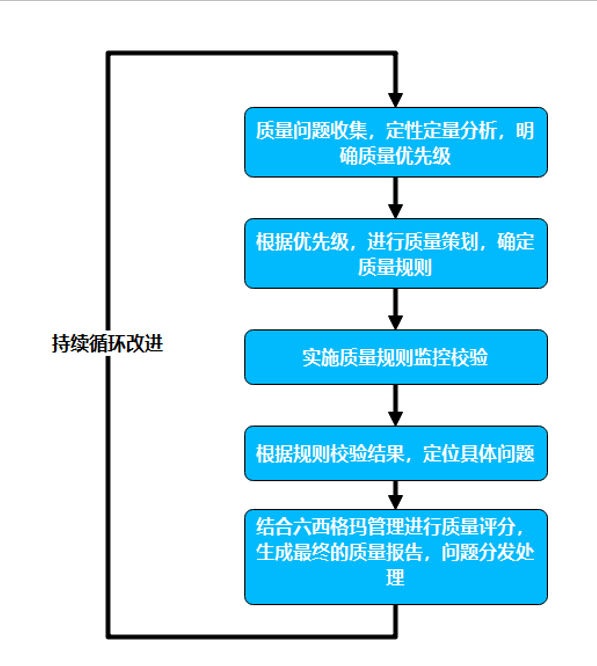
数据治理工具
开源框架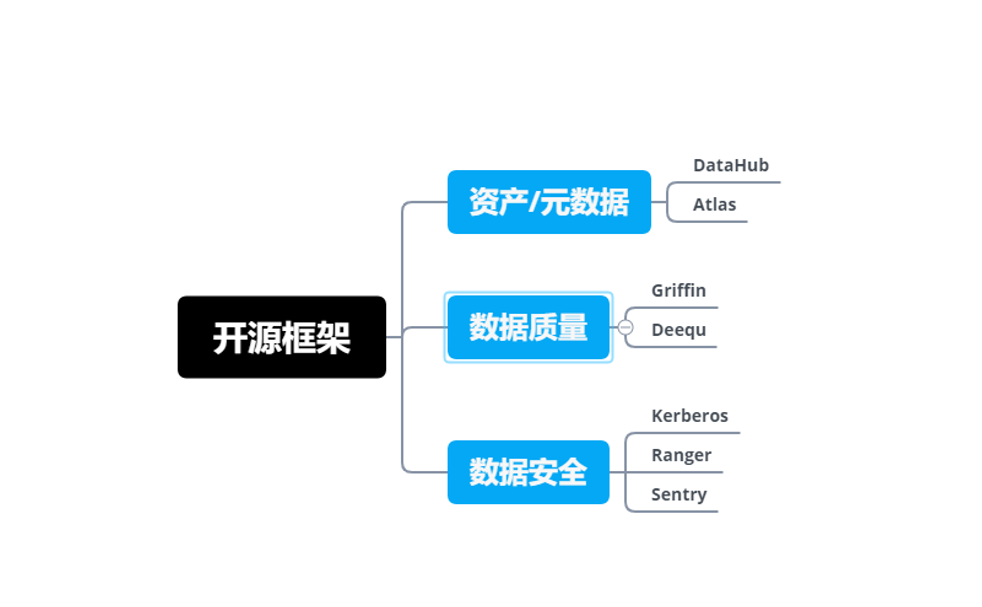
大数据测试工具
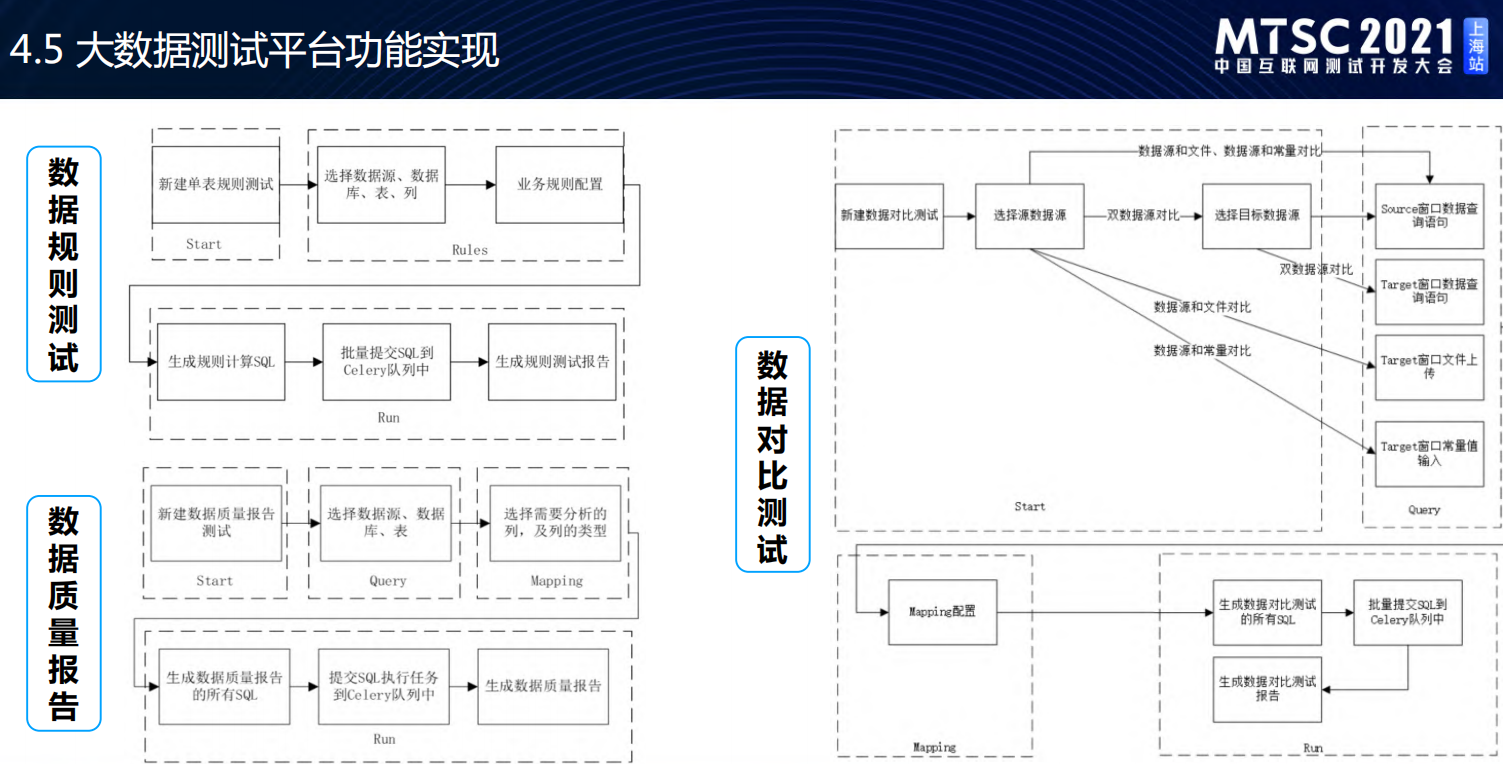
大数据测试平台架构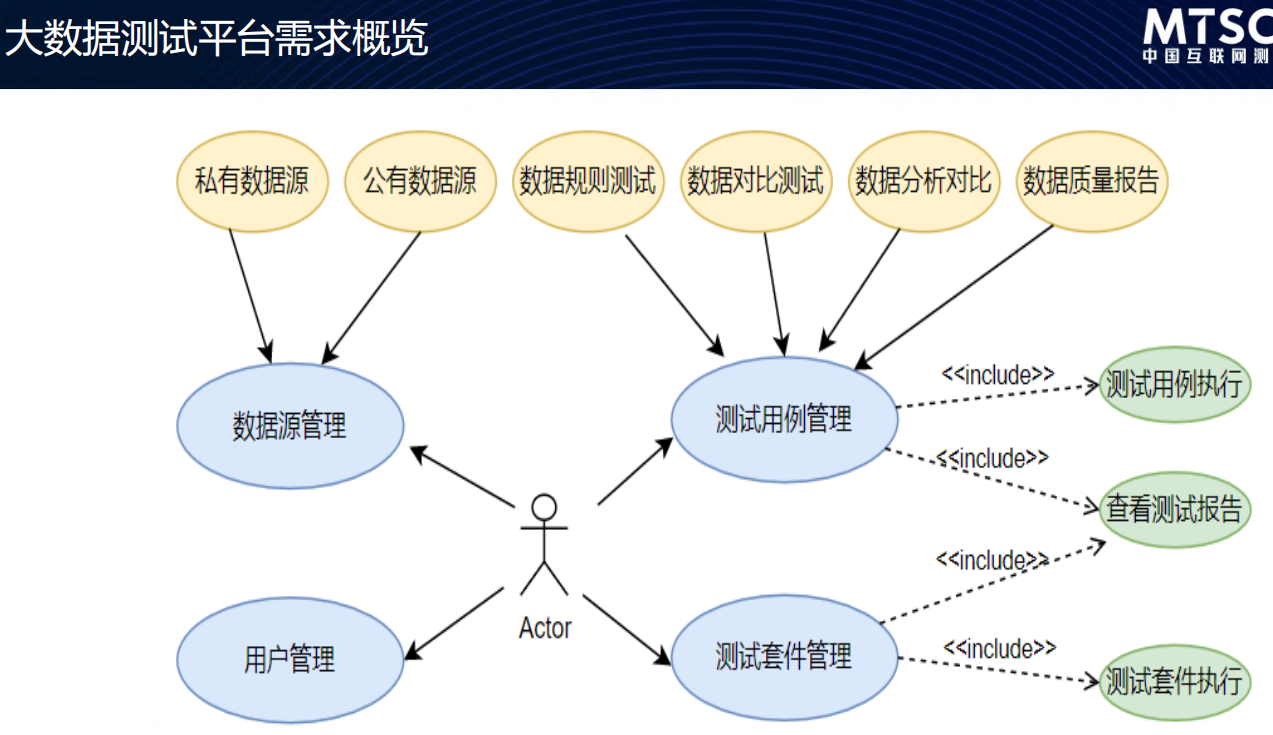
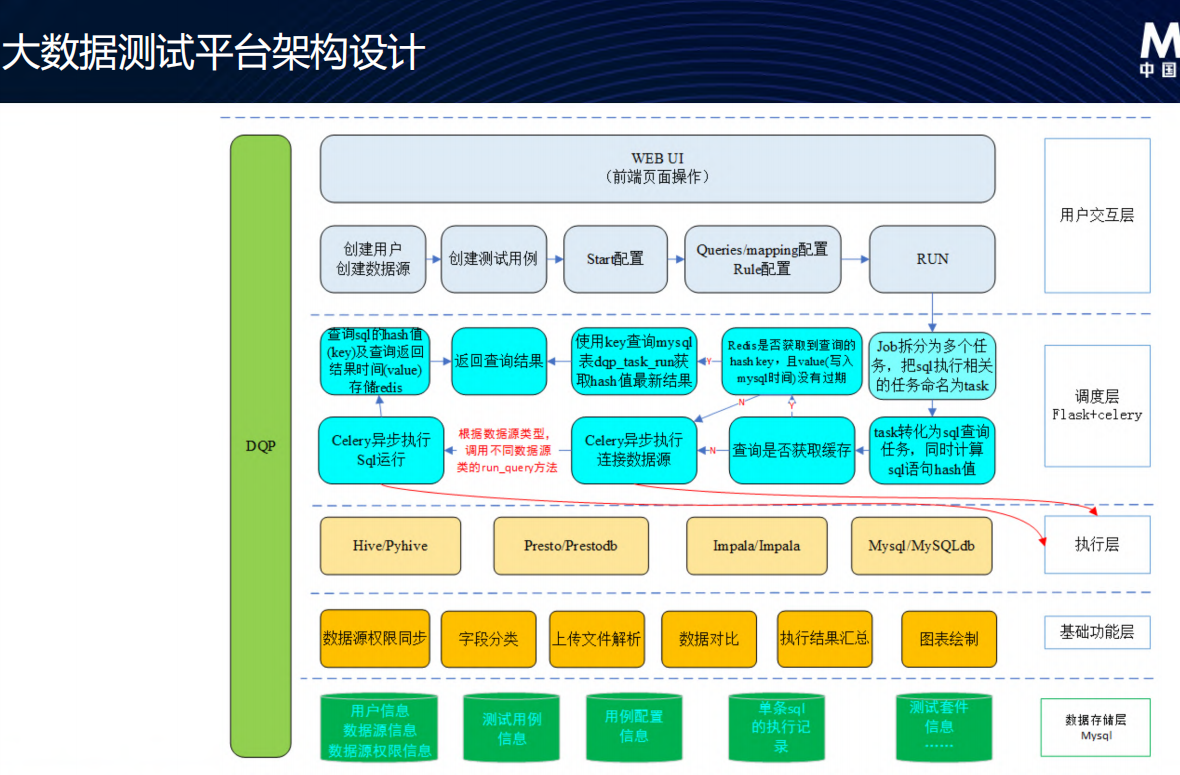
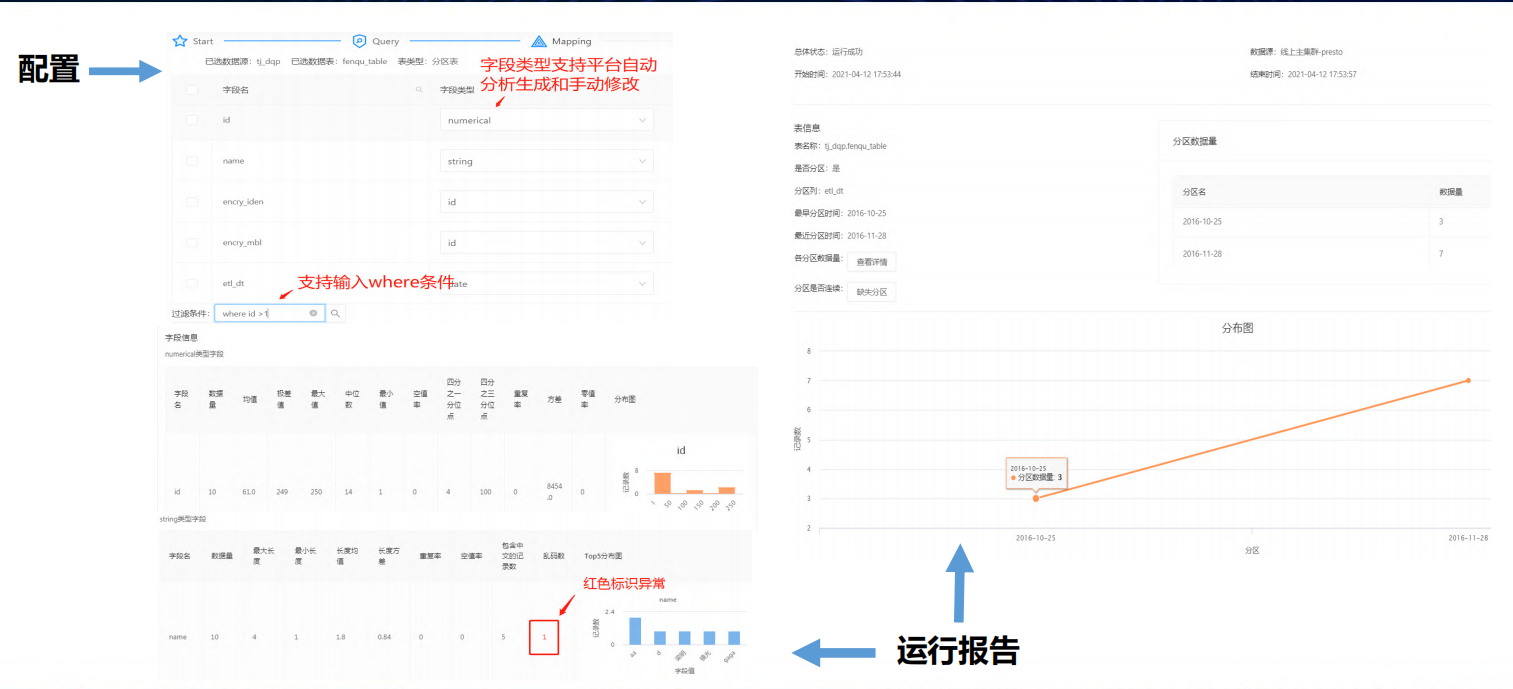
- 大数据测试平台-参考质量报告
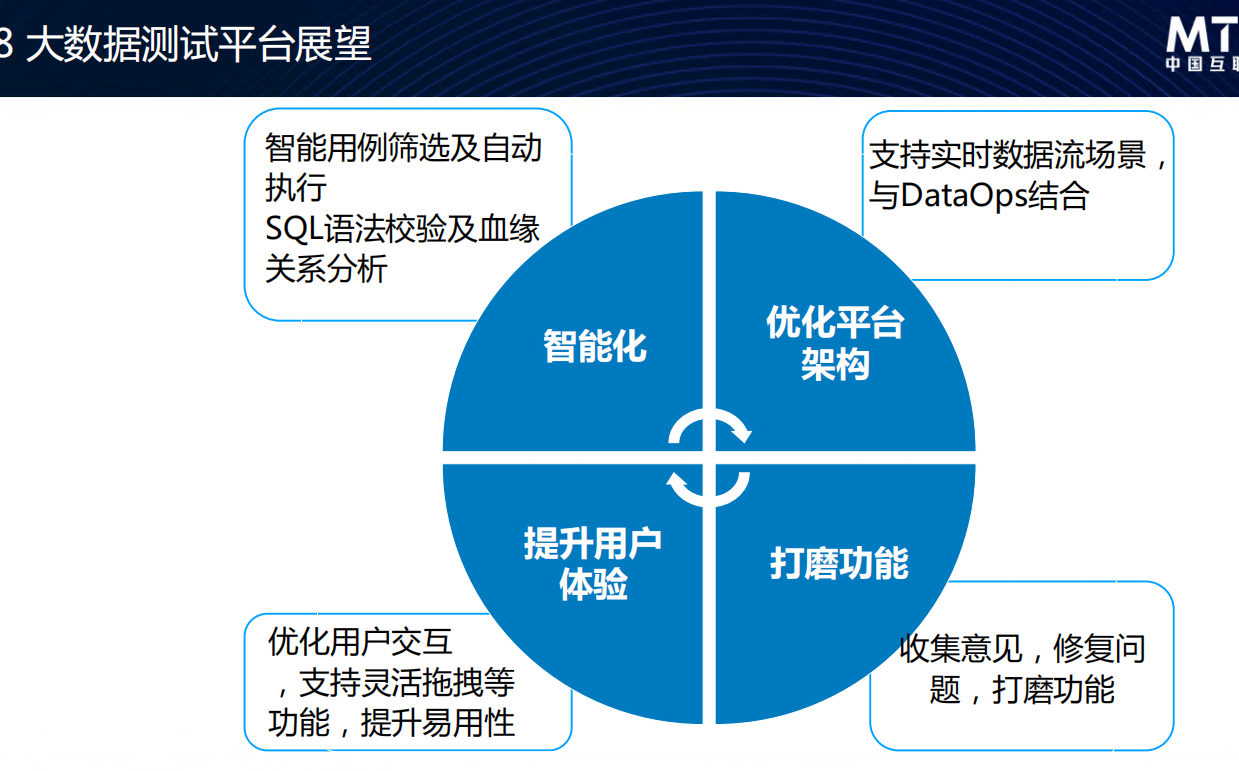
- 展望:看起来是朝线上监控化的方向走
模型测试
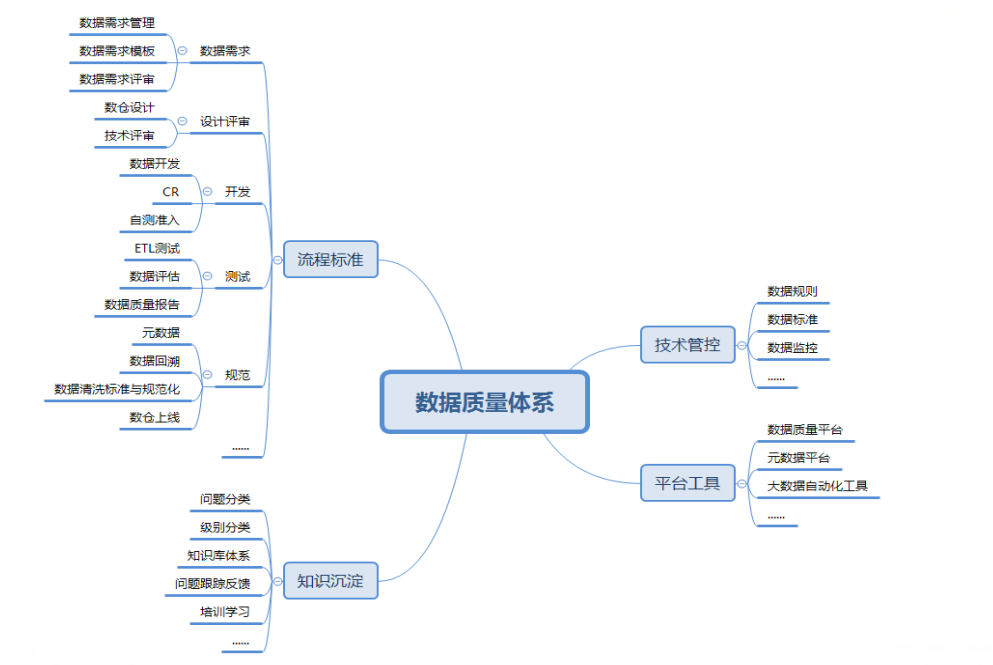
大数据质量体系
数据质量活动需要遵循:有标准、有数据(监控)、可量化(度量)、自动化的原则;质量体系总结如下: